Sure, you can hit me up on https://twitter.com/aphelionz
1 Like

1 Like
Is the crunchy filter option inclusive or exclusive?
Inclusive. Setting:
--filter-type <FILTER_TYPE>
means that only nodes matching FILTER_TYPE will be included in output.
1 Like
Thank you so much! I enjoyed doing this. 3D and crypto both have a lot of math, which I love doing in code: making something real out of theory and abstractness.
1 Like
How do I run the crawler to generate my own sample file? Is that with the ips core script? Or is there more to that?
Hi!
Sample command you can execute from the root repo directory (just replace IP and PORT with starting peer - either DNS seeder or any zcash node):
cargo run --release --features crawler --bin crawler -- --seed-addrs "IP:PORT" --rpc-addr 127.0.0.1:54321
And then just grab the results from running crawler from the other console:
curl --data-binary '{"jsonrpc": "2.0", "id":0, "method": "getmetrics", "params": [] }' -H 'content-type: application/json' http://127.0.0.1:54321/ > latest.json
It will dump results in the JSON file. Please give the crawler some time to work ![]() The progress will be printed on the console (you will see the messages about generating summary - that summary can be then taken using
The progress will be printed on the console (you will see the messages about generating summary - that summary can be then taken using curl).
Please also look at the:
https://github.com/runziggurat/zcash/blob/main/src/tools/crawler/README.md
to get some more information about the crawler.
Regards!
3 Likes
The picture describes the ‘state → ips → peer’ file loop from crunchy feeding back into the crawler. Would I extract those peers and set them as the crawler seed addrs?
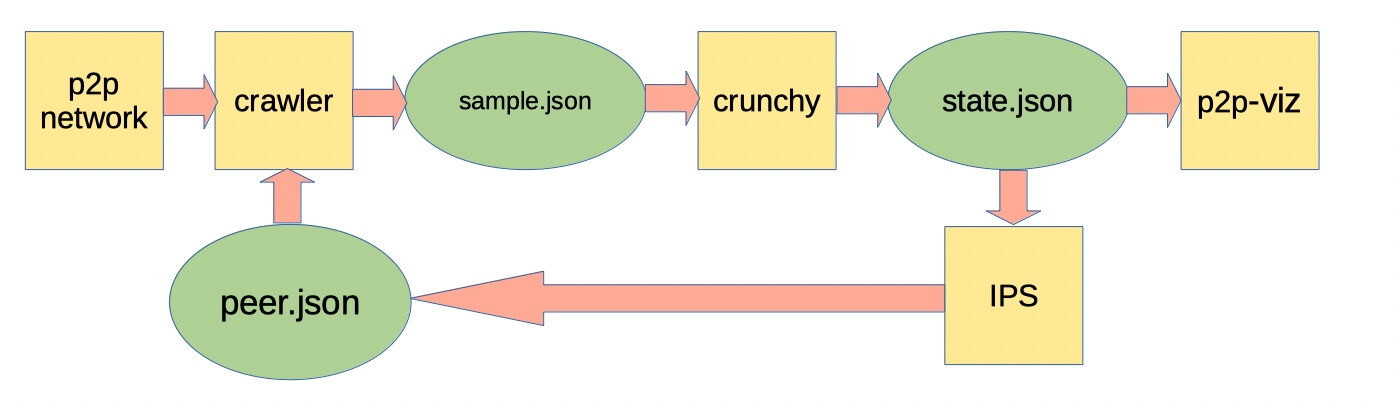
crunchy produces output both for p2p-viz and for IPS module. IPS module uses crunchy state and produces peer.json which is generally a plain JSON file.
You can always open it under any text editor and grab peers manually.
peer.json is not used by the crawler as a new seed source. Crawler can use this file to get peers which should be proposed to the particular node. It means, when the node is crawled, crawler can send to it addr message containing peer addresses. If the node accepts or decline them, it is a separate case and it is connected with network peering behaviour (policy about accepting/declining address proposals and peer sharing rules).
1 Like
I’ve noticed that running the crawler at different intervals produces slightly varied results. On the default five second interval it finds about 185-ish nodes total, only two of which are zebra nodes and that’s both for an amount of crawl time between a few minutes and a day.
Running the crawler on a 100 second interval (obviously for a little bit longer) finds about 150-ish nodes total but this time six or seven zebras which is closer to what is believed to be the actual amount running between myself and some other devs at the ZFND.
Have you experienced this? Do you have any thoughts or insight perhaps as to why the intensity of the crawl may be changing the results? The intensity/interval is what was first suggested as being potentially actionable here.
1 Like
Different intervals shouldn’t influence on the crawler results. Crawler interval says mainly how often main loop of the application is executed and how often it should scan both known and not known network searching for nodes to connect to. Basically, new peers are crawled instantly, while those ones which has been crawled in the past, would be crawled again after some time.
Different results on how many Zebra nodes are found can be caused by some other reasons. First reason can be connected with the way that peerlists are returned. Vast majority of nodes return 1k addresses but they know it much more - lists are randomized and during single run you can find different set of nodes. However, running crawler long enough should cause that the same peers would be visited more than once, allowing to get more peers. The second reason can be connected with Zebra behaviour we’ve observed - there are some time slots when Zebra stops responding for incoming connections, especially under heavy load. If crawler hits such slot it won’t get connected and won’t add that Zebra to the list of known nodes. Moreover, if Zebra node would be added initially to the known network and won’t respond when crawler will try to connect to it again, it won’t be reported in the final JSON file. We can discuss this problem on Discord.
2 Likes
This is likely due to some of Zebra’s security features:
- peer connection count limits
- new peer connection rate limits
- disconnecting some peers when Zebra is under heavy load
If this impacts your use case, we can adjust these parameters, but in general standard node usage shouldn’t reach them, unless there are other peers or scanners are behaving badly.
3 Likes
So, we are aware there are more than eight zebra nodes in the network.
And that’s because we are monitoring active connections in our zcashd node, where we can currently observe eight zebrad nodes which are now connected to our zcashd node. The other 22 connections are from zcashd nodes.
And only two of those zebra nodes are reachable to us (when we try to initiate a connection), and we can crawl those anytime. Our crawler managed to detect those two easily. So these two nodes are behaving normally the most time of the day and seem to be in a healthy state.
But the other six zebrad seem to be in some state where they are either constantly under heavy load or there’s some other issue here.
We can observe the same issue with our local zebrad node - there’s something strange in the logs, and during this time, the zebrad cannot accept inbound connections - and we tried to help and recover the zebrad with some methods, but nothing helps, and we can observe that we have plenty of CPU/memory resources on the system.
We observed this issue only because we were stubbornly trying to establish a connection towards these zebra because we were aware these nodes were in the network, but then we wondered why we could not reach those nodes. This kind of explains why we don’t see many zebrad nodes in our crawler report.
2 Likes
Maybe those nodes don’t have a public IP address?
This is a configuration choice, and some nodes can only make outbound connections due to NAT or firewalls. (zcashd can do this too if it is configured that way.)
For anyone who is interested, we’re working through other potential bugs in Zebra in Discord:
2 Likes
Okay, we have set up the inverse crawler (the node that just sits in the network and waits for inbound connections) to catch and inspect these hidden zebrad nodes in the network.
This is a configuration choice, and some nodes can only make outbound connections due to NAT or firewalls. (
zcashdcan do this too if it is configured that way.)
And indeed! It seems like some of these zebrad nodes are hidden behind a firewall (or don’t have a listening IP), so our normal crawler can’t reach those.
That got us thinking - we could extend the crawler with some passive, silent listener to hunt down those invisible nodes in the network.
Also, an interesting unrelated finding:
Some of the zebrad nodes we found often create two connections to our listening node
2 Likes
Does your listening node have multiple public IP addresses?
We’ve just fixed a bug in Zebra that could have made our address book peer state get overwritten with an older state. So please wait for the next release and re-test for this issue.
2 Likes
Does your listening node have multiple public IP addresses?
Our listening node uses just one public address - but we do have multiple different nodes on the same address. One node uses 8233, and the other nodes pick a random port.
We’ve just fixed a bug in Zebra that could have made our address book peer state get overwritten with an older state. So please wait for the next release and re-test for this issue.
We left our synth node running for a few days, and then when we came back online on Monday, we found one of those ‘hidden’ zebrad created nine connections towards our synth node - so we can easily re-test this for the next release.
Just making sure: do these connections all last for exactly the same time, or are they only overlapping for a short while? Or do they not overlap at all?
Because the way our code is set up, the overlap should only be around 30 seconds. (Depending on exactly what it causing it.)
Okay, let us show you our output from Monday (I’ll hide the actual IP here) - and this zebra node here reports the Zebra:1.0.0-rc.8 version in the handshake procedure.
IP:61725 (Initiator) connection established for 261659.187967142 seconds
IP:63300 (Initiator) connection established for 200290.488654367 seconds
IP:63475 (Initiator) connection established for 186612.76220032 seconds
IP:49607 (Initiator) connection established for 153232.705936181 seconds
IP:49860 (Initiator) connection established for 146238.805304459 seconds
IP:52390 (Initiator) connection established for 122062.857630915 seconds
IP:53090 (Initiator) connection established for 116131.909325629 seconds
IP:57706 (Initiator) connection established for 111394.034115723 seconds
IP:60784 (Initiator) connection established for 109360.912254869 seconds
So it’s a mix of both. In the above printout, we only show the currently active connections, it doesn’t have any historical connections, so there might have been established more than nine connections at some time.
From what we see, this issue seems to be more common with unreachable zebra nodes.
But there was also one case with one reachable Zebra:1.0.0-rc.7, which also created three non-overlapping connections:
IP2:41406 (Initiator) connection established for 208085.12634777 seconds
IP2:56146 (Initiator) connection established for 148684.528463004 seconds
IP2:36398 (Initiator) connection established for 20099.454923311 seconds
Thanks for helping us diagnose this, if it is the bug I’m thinking of, it should be fixed in 1.0.0-rc.9.
Do you know if there are multiple Zebra instances behind that IP address?
I think we’ll only treat this as a bug if a single Zebra instance makes multiple outbound connections to the same IP address, and they overlap for a long while.
It could be valid node behaviour to:
- make a new connection and then close the old one,
- connect via multiple addresses to the same node, or
- accept multiple inbound connections from the same IP (because we have no way of telling the difference between NAT, multiple instances on the same IP, and multiple connections from a single instance)
3 Likes