For those interested, timestamp was adjusted 3000 or 4000 seconds forward on blocks 1194 and 1712 with no followup manipulation, and small errors in 3 other timestamps.
About 2.5% took >7.5 minutes after the difficulty stopped its steady rise. About 2.5% took less than 30 seconds. It should have been 5% and 18%, so it’s not a Poisson process. I believe the low end is from there being a bare minimum time to solve.
That minimum solve time arises out of input data that, through chance, presents a least-challenging sorting process. It’s something miners have no control over. What miners can control to improve their individual hashrate is their amount of processing power and memory bandwidth.
On a related topic, how can i determine the network’s current hash rate?
Is it the networkhashps in getmininginfo ?
If so, is the rate in the same units you’d get when you do 2 divided by average time to run the “zcbenchmark solveequihash 10” test?
This is a perl script that will parse your debug.log file to get hash IDs as inputs for zcash-cli to get difficulty for your own block explorer. If log2_work in debug.log has some conversion factor to difficulty, it could get by with just the debug file and be a lot faster. Debug.log will include canceled blocks, showing something block explorer doesn’t. It’s an ugly method, but I didn’t know how else to get blocknum, time, and difficulty. Save as a file in the folder above zcash and run with perl filename.
open (F,"<.zcash/testnet3/debug.log"); @a=<F>; close F;
foreach $a (@a) {
if ($a=~/.+best=([^ ]+).+height=(\d+).+date=\d\d\d\d-\d\d-(\d\d) (\d\d):(\d\d):(\d\d).+/) {
$block=$2;
$secs=$3*24*3600+$4*3600+$5*60+$6;
$info=`./zcash/src/zcash-cli getblock $1`; # 1 is hash
$info=~m/"difficulty" : (\d+)/sg;
$diff=$1;
$sum=$thissecs;
$thissecs=$secs-$lastsecs;
$sum+=$thissecs;
if ($sum/300 < .22 or $sum/500 > 2.3) { $anomoly=" ***"; }
$blocks[$block]="$block\t$secs\t$thissecs\t$diff\t$anomoly\n";
$anomoly="";
$lastsecs=$secs;
$check = 'yes';
}
}
open (F,">difficulty.txt"); print F @blocks; close F;
exit;
About hash rate - if i am getting a block every 30 minutes, then does that mean that i got about 8% of the network power?
Then, by the formula in the benchmark article, the hash rate is difficulty divided by 10, not multiplied by 25.
Yes, if you’re getting a block every 30 minutes, you have 1/12 = 8% network power. From that you should be able to determine relation between difficulty and hashrate, since you know your hash rate per core. Make sure divide equisolve’s seconds output for a single core by 2.
There seem to be 1.1 x Difficulty number of 4-core CPUs on the network (by my measurements of my block solves per total blocks) that can solve in an average of 35 seconds / 2 = 17.5 secs / hash. Divide by 2 because the solver (last I heard) shows the time for 2 solves, not 1. So network hash rate appears to be Diff = 50 gives 50 x 1.1 x 4 x 1/17.5 = 12.5 hashes per second, more like hash rate = D / 4. It seems “benchmark article” (where is it? ) didn’t take into account there are 2 hashes per solve, or the solver has been fixed to reflect hashes directly by dividing by two, which would have given me D/8 = hashes per second.
You misunderstand the sentence you quoted. I said that the time to first solution is around 30s (for the machines I’ve tested on). I’ve also said previously that on those same machines, it’s about 15s to finish the main solver, and then 15s per solution found. So:
15s to find 0 solutions
30s to find 1 solution
45s to find 2 solutions (but the first one is output from the solver at 30s)
etc.
When the solver is reworked as a work queue (#1239) this should drop to around 30s to find all solutions (at least for fewer solutions than available cores).
There continues to be about 3000 seconds added to the timestamp once or twice a day, but no obvious follow-up behavior like before.
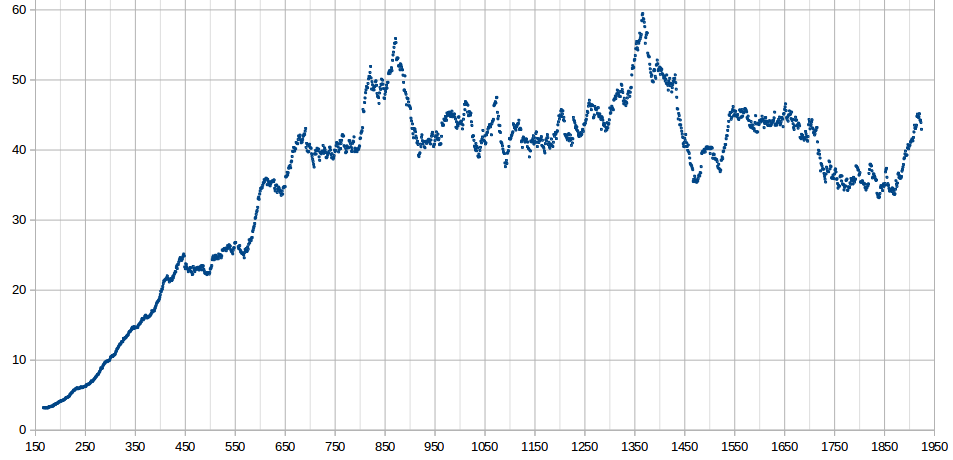
The difficulty so far on beta is shown below. This is equal to the number “fast CPUs” on the network. “Fast” means the CPU can get about 38 second voles on the benchmark. This is by observation instead of trying to calculate hashrate.
Note that occasional future timestamps could be due to accidental clock errors. As long as there are not 6 consecutive erroneous timestamps, that would not have any large effect on difficulty (because of the median-of-11 averaging).